چارچوبهای استراتژیک و محاسباتی برای دستیابی به دقت ۹۵ درصد در پیشبینی درآمد بیمارستان
مقدمه اجرایی: ضرورت دقت در عصر عدم قطعیت
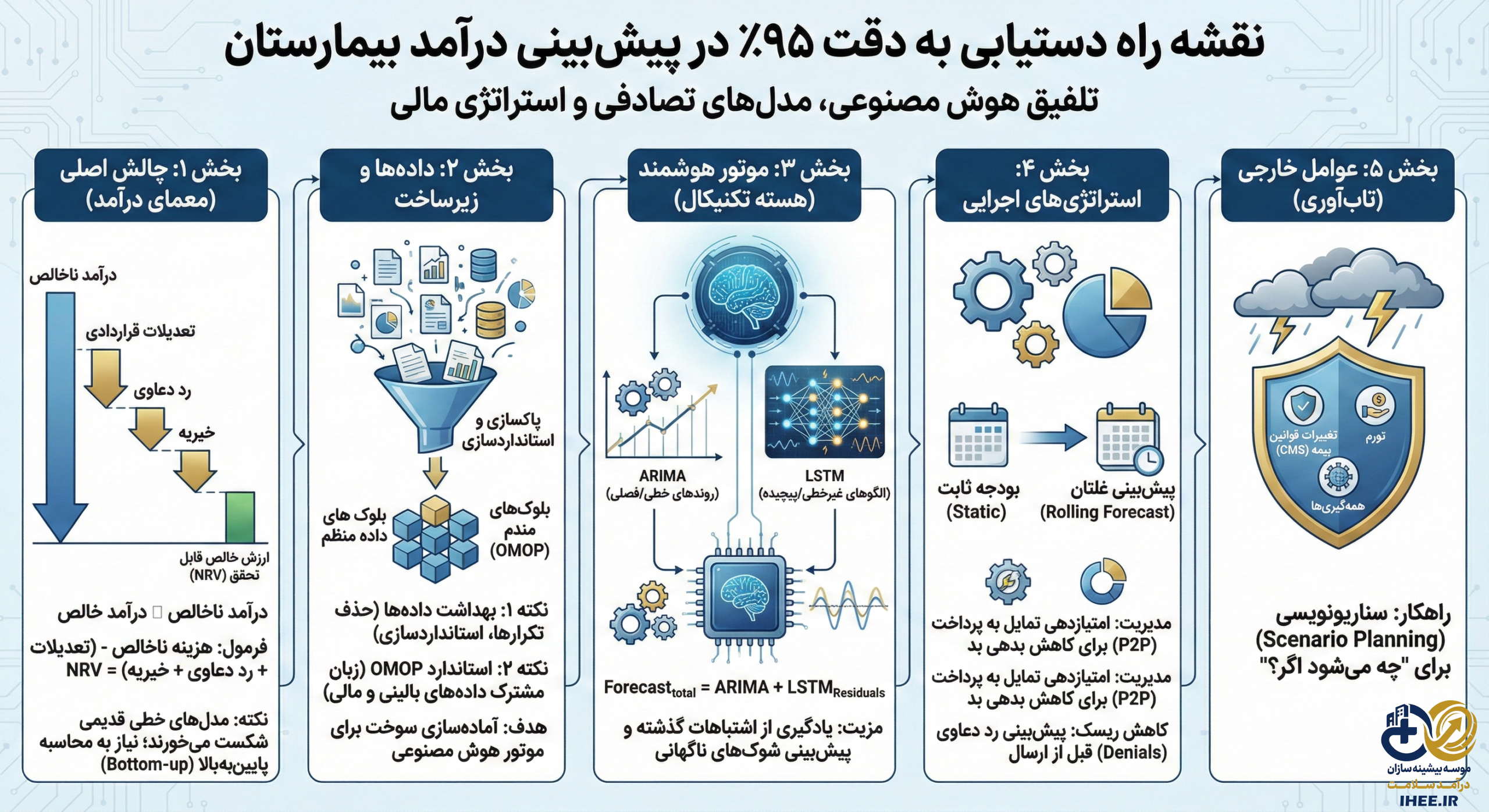
در اکوسیستم پیچیده و پویای مراقبتهای بهداشتی مدرن، ثبات مالی بیمارستانها دیگر تابعی خطی از حجم بیماران ورودی نیست؛ بلکه مشتقی پیچیده از دقت پیشبینیهاست. توانایی پیشبینی درآمد بیمارستان با دقت ۹۵ درصد، از یک هدف آرمانی به یک ضرورت رقابتی و حیاتی برای بقا تبدیل شده است.۱ بیمارستانها و سیستمهای بهداشتی که همچنان بر مدلهای بودجهریزی سنتی و ایستا تکیه دارند، با واریانسهای غیرقابلتوجیهی مواجه میشوند که نقدینگی، تخصیص سرمایه برای فناوریهای پزشکی حیاتی و تعادل نیروی انسانی را تهدید میکند. پیچیدگی ذاتی چرخه درآمد در نظام سلامت—که با شکاف عمیق میان هزینههای ناخالص (Gross Charges) و درآمد خالص قابل تحقق (Net Realizable Revenue)، ترکیب متغیر پرداختکنندگان (Payer Mix) و الگوهای مبهم کسورات و رد دعاوی (Denials) مشخص میشود—استفاده از برونیابیهای خطی ساده را منسوخ کرده است.
دستیابی به معیار دقت ۹۵ درصد مستلزم یک تغییر پارادایم بنیادین است: گذار از تحلیلهای مبتنی بر نرخ اجرای تاریخی (Run-rate) به سمت مدلسازی تصادفی (Stochastic) و مبتنی بر محرک (Driver-based) که معماریهای یادگیری ماشین (Machine Learning) را با دانش عمیق نهادی از تغییرات نظارتی تلفیق میکند.۲ این گزارش جامع، تحلیلی exhaustive و موشکافانه از متدولوژیها، زیرساختهای دادهای و چارچوبهای استراتژیک مورد نیاز برای به حداقل رساندن انحراف معیار و بهینهسازی عملکرد مالی ارائه میدهد. در ادامه، گذار از بودجههای ثابت به پیشبینیهای غلتان (Rolling Forecasts)، پیادهسازی مدلهای ترکیبی ARIMA-LSTM و مدیریت گرانولار معیارهای چرخه درآمد نظیر شاخص ترکیب موارد (CMI) و امتیاز تمایل به پرداخت (P2P) مورد بررسی قرار میگیرد. هدف نهایی، تبیین نقشهراهی است که رهبران مالی را قادر میسازد تا در برابر نوسانات بازار و شوکهای نظارتی، تابآوری مالی سازمان خود را تضمین کنند.
فصل اول: کالبدشکافی دینامیکهای ساختاری درآمد در نظام سلامت
۱.۱ معمای تبدیل درآمد ناخالص به خالص (Gross-to-Net)
مانع بنیادین در برابر پیشبینی دقیق درآمد در حوزه بهداشت و درمان، رابطه غیرخطی و اغلب گمراهکننده میان درآمد خدمات بیمار (GPSR) و درآمد خالص خدمات بیمار (NPSR) است. برخلاف بخشهای خردهفروشی یا تولید که در آنها قیمت نهایی کالا ثابت و مشخص است، درآمد بیمارستان تابعی از یک ماتریس پیچیده شامل تخفیفات قراردادی (Contractual Allowances)، مراقبتهای خیریه (Charity Care) و بدهیهای بد (Bad Debt) است.۳
یک پیشبینی که صرفاً بر اساس هزینههای صورتحساب شده (Billed Charges) بنا شده باشد، ناگزیر با شکست مواجه خواهد شد، زیرا فرآیند رسیدگی و تعدیل دعاوی (Adjudication Process) را نادیده میگیرد. برای دستیابی به دقت بالای ۹۵ درصد، مدلهای مالی باید ارزش خالص قابل تحقق (Net Realizable Value – NRV) را در سطح هر دعوی (Claim-level) و پیش از تجمیع محاسبه کنند. این امر مستلزم درک عمیق و مدلسازی دقیق “آبشار” کسورات است:
- هزینههای ناخالص (Gross Charges): نرخهای تعیینشده در لیست تعرفهها (Chargemaster).
- تعدیلات قراردادی (Contractual Adjustments): تفاوت میان نرخ تعرفه و نرخ توافقشده با بیمهگر (به عنوان مثال، نرخ مجاز مدیکر یا بیمههای تجاری).
- تعدیلات رسیدگی (Adjudication Adjustments): شامل رد دعاوی، کاهش سطح خدمات (Downgrades) و منطقهای بستهبندی خدمات (Bundling Logic).
- سهم بیمار (Patient Liability): فرانشیزها (Deductibles) و پرداختهای مشترک (Co-pays).
- بدهی بد/خیریه (Bad Debt/Charity): بخشهایی از سهم بیمار که غیرقابل وصول تشخیص داده میشوند.
بهترین تجربیات جهانی نشان میدهد که دقت پیشبینی زمانی به شدت کاهش مییابد که مدلها بر اساس میانگینهای بالا-به-پایین (Top-down averages) از این تعدیلات ساخته شوند. در مقابل، یک رویکرد پایین-به-بالا (Bottom-up) که منطق قراردادهای خاص را بر حجمهای پیشبینیشده برای هر خط خدماتی اعمال میکند، ضروری است.۴ این رویکرد به تحلیلگران اجازه میدهد تا تاثیر دقیق تغییرات در حجم خدمات خاص را بر درآمد خالص نهایی شبیهسازی کنند، نه اینکه صرفاً یک درصد کلی از درآمد را به عنوان کسورات در نظر بگیرند.
۱.۲ نوسانات ناشی از ترکیب پرداختکنندگان (Payer Mix)
ترکیب سبد پرداختکنندگان یک بیمارستان، یکی از تعیینکنندههای اصلی نوسانات درآمد است. بیمهگران تجاری معمولاً با نرخهایی به مراتب بالاتر از پرداختکنندگان دولتی بازپرداخت میکنند—اغلب بین ۱۴۱ تا ۲۵۹ درصد نرخهای مدیکر.۵ در نتیجه، یک انحراف جزئی در ترکیب پیشبینیشده پرداختکنندگان میتواند تأثیری نامتناسب و بزرگ بر سود نهایی داشته باشد.
جدول زیر تفاوتهای ساختاری و ریسکهای مرتبط با هر دسته از پرداختکنندگان را نشان میدهد:
| دسته پرداختکننده | نوسانپذیری سهم درآمد | واریانس بازپرداخت نسبت به هزینه | عامل ریسک در پیشبینی |
| تجاری/خصوصی | بالا | بالا (>۱۴۰٪ تعرفه دولتی) | مذاکرات مجدد قراردادها، تغییر طرحهای بیمه کارفرمایان |
| مدیکر (دولتی سالمندان) | پایین (باثبات) | متوسط (اغلب <۱۰۰٪ هزینه) | کاهشهای نظارتی (CMS)، تعدیلات بودجهای فدرال |
| مدیکید (دولتی کمدرآمد) | متوسط | پایین (کمترین نرخ بازپرداخت) | تغییرات بودجه ایالتی، بازبینی صلاحیت بیمهشدگان |
| پرداخت شخصی (Self-Pay) | بالا | منفی (ریسک بالای بدهی بد) | رکود اقتصادی، نرخ بیکاری، طرحهای بیمه با فرانشیز بالا |
تحلیلها نشان میدهند بیمارستانهایی که سهم بالاتری از بیمههای تجاری دارند، عموماً حاشیه سود بالاتری را تجربه میکنند، اما در عین حال نسبت به تغییرات اقتصادی که منجر به بیکاری و از دست رفتن پوشش بیمه خصوصی میشود، آسیبپذیرتر هستند.۵ پیشبینی دقیق مستلزم مدلسازی سناریوهای “مهاجرت پرداختکننده” (Payer Migration) است—پیشبینی اینکه چه تعداد از بیماران ممکن است در طول انقباضات اقتصادی از پوشش تجاری به پوششهای حمایتی یا پرداخت شخصی تغییر وضعیت دهند. این پدیده بهویژه در دوران پس از همهگیری کرونا و تغییرات بازار کار اهمیت دوچندانی یافته است.
۱.۳ شاخص ترکیب موارد (CMI) و شدت بیماری
شاخص ترکیب موارد (Case Mix Index – CMI) به عنوان یک نماگر عددی از شدت منابع مورد نیاز و پیچیدگی بالینی جمعیت بیماران عمل میکند. از آنجا که بازپرداختها—بهویژه در سیستمهای گروههای تشخیصی وابسته (DRG)—مستقیماً به CMI گره خوردهاند، پیشبینی حجم بیماران بدون در نظر گرفتن تغییرات شدت بیماری منجر به واریانس قابلتوجهی در درآمد خواهد شد.۷
غالباً شکافی میان تیمهای مالی که “پذیرشها” را پیشبینی میکنند و تیمهای بالینی که “شیوع بیماری” را رصد میکنند، وجود دارد. برای پر کردن این شکاف، مدلهای درآمدی باید روندهای بهبود مستندسازی بالینی (CDI) را ادغام کنند. اگر بیمارستانی برنامهای برای بهبود مستندسازی اجرا کند تا بیماریهای همراه (Comorbidities/MCCs) را بهتر ثبت کند، CMI افزایش مییابد و درآمد حتی با ثابت ماندن حجم بیماران بالا میرود. عدم لحاظ کردن این “افزایش ناشی از مستندسازی” (Documentation Lift) منجر به کمبرآورد کردن درآمد میشود؛ در مقابل، نادیده گرفتن ممیزیهای دقیق بیمهگران که منجر به تنزل کد DRG میشود، به بیشبرآورد درآمد میانجامد.۸ دقت ۹۵ درصدی مستلزم آن است که تغییرات CMI نه به عنوان یک عدد ثابت، بلکه به عنوان یک متغیر پویا و وابسته به فصل و روندهای اپیدمیولوژیک مدلسازی شود.
فصل دوم: معماری دادهها و مهندسی ویژگیها برای دقت پیشبینی
۲.۱ چالش “دادههای کثیف” و بهداشت اطلاعات
دستیابی به دقت ۹۵ درصد با دادههای پراکنده و آلوده، از نظر ریاضی غیرممکن است. دادههای مراقبتهای بهداشتی به طور سنتی در سیلوهای مجزا شامل پروندههای الکترونیک سلامت (EHR)، سیستمهای مدیریت مطب و اتاقهای پایاپای (Clearinghouses) محبوس شدهاند. مسائل رایج کیفیت داده که پیشبینیها را از مسیر خارج میکنند شامل سوابق تکراری بیماران، اطلاعات ناقص پرداختکننده و فرمتهای کدگذاری ناسازگار است.۹
پروفایلسازی و پاکسازی دادهها گامهای پیشنیاز حیاتی هستند. این فرآیند شامل موارد زیر است:
- تکرارزدایی (De-duplication): استفاده از شاخصهای اصلی بیمار (MPI) برای اطمینان از شمارش منحصر به فرد بیماران. وجود سوابق تکراری میتواند منجر به بیشبرآورد حجم بیماران و انحراف در تحلیلهای کوهورت شود.۹
- نرمالسازی (Normalization): نگاشت استانداردهای کدگذاری متفاوت (مانند تبدیل کدهای خدمات محلی به کدهای استاندارد CPT یا ICD-10) به یک استاندارد واحد برای ایجاد یکپارچگی در تحلیلهای طولی.
- جایگزینی دادههای مفقوده (Imputation): پرداختن به مقادیر گمشده در مجموعه دادههای تاریخی، مانند دلایل ثبتنشده رد دعاوی یا منابع ارجاع، با استفاده از روشهای آماری جایگزینی به جای حذف سوابق که میتواند باعث از دست رفتن اطلاعات ارزشمند شود.۹
۲.۲ استانداردسازی از طریق مدل دادههای مشترک OMOP
برای فعالسازی تحلیلهای پیشرفته، موسسات پیشرو در حال تبدیل دادههای خام EHR به مدل دادههای مشترک OMOP (Observational Medical Outcomes Partnership) هستند. استاندارد OMOP ساختار و معناشناسی دادهها را یکسانسازی میکند و امکان ادغام رخدادهای بالینی، مواجهات دارویی و وقوع شرایط پزشکی را در فرمتی بهینهشده برای تحلیلهای مقیاسبزرگ فراهم میآورد.۱۰
با تبدیل دادههای اختصاصی و پراکنده EHR به فرمت OMOP، بیمارستانها میتوانند الگوریتمهای پیشبینی استانداردی را مستقر کنند که در سطح صنعت اعتبارسنجی شدهاند. این قابلیت همکاری (Interoperability) برای بنچمارک کردن عملکرد درآمد در برابر موسسات همتایان—که یکی از اجزای کلیدی ابتکار MAP انجمن مدیریت مالی بهداشت و درمان (HFMA) است—حیاتی میباشد.۱۲ این استانداردسازی به مدلهای یادگیری ماشین اجازه میدهد تا الگوهای پنهان در دادههای بالینی را که مستقیماً بر درآمد تأثیر میگذارند (مانند شدت بیماری و احتمال بستری مجدد) شناسایی کنند.
۲.۳ مهندسی ویژگیها برای یادگیری ماشین
برای اینکه مدلهای یادگیری ماشین بتوانند درآمد را بهطور موثر پیشبینی کنند، دادههای خام باید به “ویژگیهای” (Features) معنادار تبدیل شوند. مهندسی ویژگی به مدلها اجازه میدهد الگوهای ظریفی را که تحلیلگران انسانی ممکن است نادیده بگیرند، شناسایی کنند.
ویژگیهای حیاتی برای پیشبینی درآمد:
- ویژگیهای زمانی (Temporal Features): روز هفته، ماه، تعطیلات و شاخصهای فصلی (مانند شدت فصل آنفولانزا) که تأثیر مستقیمی بر حجم مراجعات اورژانس و الکتیو دارند.۱۳
- متغیرهای تأخیری (Lagged Variables): درآمد حاصل از $t-1$، $t-7$ و $t-30$ روز قبل برای ثبت خودهمبستگی (Autocorrelation) و روندهای کوتاهمدت.
- متریکهای عملیاتی: نرخ اشغال تخت، بهرهوری اتاق عمل (OR Utilization) و نسبت نیروی انسانی به بیمار.۱۵
- ویژگیهای بالینی: کدهای تشخیص اولیه، تعداد پروسیجرها و شاخصهای بیماریهای همراه (مانند شاخص چارلسون) که شدت و هزینه درمان را پیشبینی میکنند.۱۳
- شاخصهای اجتماعی-اقتصادی: دادههای درآمدی در سطح کد پستی برای پیشبینی قابلیت وصول پرداختهای شخصی و ریسک بدهی بد.۱۶
مطالعات موردی نشان میدهند که ترکیب متغیرهای مالی (مانند مبلغ صورتحساب) با الگوهای زمانی، قویترین پیشبینیکنندههای ریسک تقلب و رد دعاوی هستند و در برخی چارچوبهای تشخیص تقلب تا ۹۱٪ از قدرت پیشبینی مدل را تشکیل میدهند.۱۷ این امر بر اهمیت ادغام دادههای بالینی، عملیاتی و مالی در یک مدل واحد تأکید میکند.
فصل سوم: متدولوژیهای استراتژیک؛ گذار از بودجهریزی ایستا به پیشبینیهای غلتان
۳.۱ ناکارآمدی بودجهریزی سنتی
بودجهریزی ایستا—ایجاد یک بودجه ثابت برای کل سال مالی—در محیط پرنوسان بهداشت و درمان به طور فزایندهای به عنوان یک بدهی و محدودیت تلقی میشود. تا سه ماهه دوم سال، فرضیات زیربنایی یک بودجه ثابت اغلب به دلیل تغییرات نظارتی، شیوع بیماریهای پیشبینینشده یا تغییرات در رفتار پرداختکنندگان منسوخ میشوند.۱۸ تکیه بر بودجهای که دیگر با واقعیت همخوانی ندارد، منجر به تصمیمات نادرست در تخصیص منابع و مدیریت نقدینگی میشود.
۳.۲ مدل پیشبینی غلتان (Rolling Forecast)
پیشبینیهای غلتان به طور مداوم تخمینها را بهروزرسانی میکنند، معمولاً با افزودن یک ماه یا سه ماهه جدید همزمان با پایان یافتن دوره جاری. این رویکرد دید رو به جلوی ۱۲ تا ۱۸ ماهه را به طور پیوسته حفظ میکند.۲۰
مزایای کلیدی این مدل عبارتند از:
- چابکی (Agility): امکان بازتنظیم فوری تخصیص منابع در پاسخ به جهشهای ناگهانی در استفاده از خدمات (مانند همهگیریها) یا کاهشهای بازپرداخت را فراهم میکند.
- مبتنی بر محرک (Driver-Based): به جای تمرکز بر ردیفهای جزئی بودجه، بر محرکهای کلیدی (حجم بیماران، نرخهای بازپرداخت، هزینههای نیروی کار) تمرکز دارد. این امر اجازه میدهد تا تأثیر تغییرات در یک محرک به سرعت در کل مدل مالی شبیهسازی شود.
- تحلیل واریانس پویا: تمرکز را از مقایسه “بودجه در برابر واقعی” به “پیشبینی در برابر واقعی” تغییر میدهد. این تغییر رویکرد، فرهنگی از یادگیری مداوم و اصلاح مدل را ترویج میکند، زیرا انحرافات به عنوان سیگنالهایی برای بهبود دقت مدل در دورههای بعدی در نظر گرفته میشوند.۲۱
پیادهسازی پیشبینیهای غلتان نیازمند پذیرش فرهنگی در سازمان و خودکارسازی فرآیند ورود دادههاست تا بار اداری تیمهای مالی کاهش یابد. هدف نهایی، کاهش چرخه زمانی پیشبینی از هفتهها به روزهاست تا تصمیمگیران همواره به دادههای بهروز دسترسی داشته باشند.۲۲
۳.۳ برنامهریزی سناریو (Scenario Planning)
علاوه بر پیشبینیهای غلتان، برنامهریزی سناریو برای مدلسازی رویدادهای گسسته و شوکهای خارجی ضروری است. این روش شامل ایجاد چندین نسخه از آینده (مانند بهترین حالت، بدترین حالت، و محتملترین حالت) بر اساس تغییرات احتمالی در متغیرهای کلیدی است.۳ برای مثال، یک بیمارستان ممکن است سناریوهایی را برای تغییرات احتمالی در سیاستهای بازپرداخت CMS یا وقوع یک بحران بهداشتی جدید تدوین کند. این رویکرد به سازمان اجازه میدهد تا برنامههای اقتضایی را از پیش آماده کرده و در صورت وقوع هر سناریو، واکنش سریع و موثری نشان دهد.
فصل چهارم: مدلسازی کمی پیشرفته؛ هسته هوشمند پیشبینی
دستیابی به دقت ۹۵ درصد نیازمند استفاده از مدلهای ریاضی و آماری پیشرفتهای است که فراتر از میانگینهای متحرک ساده عمل میکنند. در این بخش، به بررسی مدلهای سری زمانی، یادگیری عمیق و معماریهای ترکیبی میپردازیم.
۴.۱ تحلیل سری زمانی: ARIMA و SARIMA
برای شناسایی روندهای خطی و فصلی در درآمد بیمارستان، مدلهای میانگین متحرک یکپارچه خودهمبسته (ARIMA) به عنوان یک خط مبنای قوی عمل میکنند.
مدل ARIMA با سه پارامتر $(p, d, q)$ تعریف میشود:
- $p$: تعداد مشاهدات تأخیری (بخش خودهمبسته – AR).
- $d$: درجه تفاضلگیری مورد نیاز برای ایستا کردن سری زمانی (Integrated).
- $q$: اندازه پنجره میانگین متحرک (Moving Average).۲۴
برای بیمارستانهایی که دارای الگوهای فصلی قوی هستند (مانند حجم بالای بستری در زمستان به دلیل بیماریهای تنفسی و کاهش جراحیهای الکتیو در تابستان)، مدل SARIMA (Seasonal ARIMA) برتر است. SARIMA پارامترهای فصلی $(P, D, Q)_s$ را اضافه میکند تا نوسانات دورهای را در نظر بگیرد.۲۴
محدودیتها: مدلهای ARIMA خطی بودن روابط را فرض میکنند و در ثبت روابط پیچیده و غیرخطی یا “شوکهای” ناگهانی (شکستهای ساختاری) در دادهها، مانند تغییر ناگهانی سیاستها یا همهگیری، دچار مشکل میشوند.۲۶
۴.۲ یادگیری عمیق: شبکههای LSTM
برای غلبه بر محدودیتهای مدلهای خطی، از حافظه کوتاه-مدت طولانی (Long Short-Term Memory – LSTM) استفاده میشود که نوعی شبکه عصبی بازگشتی (RNN) است. LSTMها برای یادگیری وابستگیهای طولانیمدت و الگوهای غیرخطی در دادههای متوالی طراحی شدهاند.۲۷
مزایای LSTM در بهداشت و درمان:
- حافظه: قادر به حفظ اطلاعات در توالیهای طولانی است، که به مدل اجازه میدهد روندهای سالهای گذشته را که ممکن است بر پیشبینیهای فعلی تأثیر بگذارند، “به خاطر بسپارد”.
- غیرخطی بودن: میتواند تعاملات پیچیده بین متغیرها را مدلسازی کند، مانند رابطه غیرخطی بین سطوح نیروی انسانی و درآمد قابل صورتحساب.
- قابلیت چندمتغیره: میتواند جریانهای ورودی متعدد را به طور همزمان پردازش کند (مانند درآمد تاریخی، دادههای آب و هوا، روندهای آنفولانزا، شاخصهای اقتصادی).۲۵
پژوهشها نشان میدهند که اگرچه LSTMها به قدرت محاسباتی و دادههای بیشتری برای آموزش نیاز دارند، اما اغلب در سناریوهایی با نوسانات بالا و ساختارهای دادهای پیچیده، عملکرد بهتری نسبت به ARIMA دارند.۲۷
۴.۳ استاندارد طلایی: مدلهای ترکیبی (Ensemble) ARIMA-LSTM
تلاش برای رسیدن به دقت ۹۵ درصد اغلب به مدلهای ترکیبی (Ensemble)، بهویژه معماری ترکیبی ARIMA-LSTM ختم میشود. این رویکرد از نقاط قوت مکمل روشهای آماری و یادگیری ماشین بهره میبرد.۲۹
معماری یک مدل ترکیبی:
- مدلسازی خطی: مدل ARIMA بر روی دادههای سری زمانی اعمال میشود تا روندهای خطی و اجزای فصلی را ثبت کند.
- محاسبه باقیماندهها: باقیماندهها (خطاها) از مدل ARIMA محاسبه میشوند. این باقیماندهها حاوی ساختار غیرخطی هستند که ARIMA نتوانسته توضیح دهد.
- مدلسازی غیرخطی: شبکه LSTM بر روی باقیماندهها آموزش داده میشود تا الگوهای غیرخطی را مدلسازی کند.
- تلفیق: پیشبینی نهایی مجموع پیشبینی ARIMA و پیشبینی باقیمانده LSTM است.
$$\text{Forecast}_{total} = \text{Forecast}_{ARIMA} + \text{Forecast}_{LSTM\_Residuals}$$
مطالعات نشان میدهند که این رویکرد ترکیبی به طور مداوم خطای درصد مطلق میانگین (MAPE) و ریشه میانگین مربعات خطا (RMSE) کمتری نسبت به هر یک از مدلها به تنهایی دارد.۳۰ این معماری بهویژه برای پیشبینی تقاضای منابع بیمارستانی و درآمد، جایی که هم روندهای فصلی قوی و هم نوسانات پیچیده و نامنظم وجود دارند، موثر است.
۴.۴ مدلهای تغییر رژیم (Regime-Switching Models)
بازارهای بهداشت و درمان در معرض “رژیمها” هستند—دورههای متمایز رفتاری که ناشی از تغییرات ساختاری هستند (مانند قبل از طرح تحول سلامت در برابر بعد از آن، یا قبل از کووید در برابر بعد از کووید). مدلهای استاندارد اغلب در طول تغییرات رژیم شکست میخورند زیرا رفتار را در دورههای متفاوت میانگین میگیرند.
مدلهای تغییر رژیم مارکوف (Markov Regime-Switching) اجازه میدهند پارامترها بسته به “حالت” جهان تغییر کنند. با محاسبه احتمال قرار گرفتن سیستم در یک رژیم خاص (مانند “رشد بالا”، “رکود”، “موج پاندمی”)، مدل میتواند پیشبینیهای خود را بر این اساس تنظیم کند.۳۳
- کاربرد: در طول یک رکود اقتصادی، یک مدل تغییر رژیم ممکن است به طور خودکار وزن احتمال بدهی بد بالاتر و حجم کمتر خدمات الکتیو را افزایش دهد، و پیشبینی را قبل از اینکه روند در دادههای خطی آشکار شود، اصلاح کند.۳۵
فصل پنجم: بهینهسازی چرخه درآمد و مدیریت هوشمند کسورات
دقت در پیشبینی درآمد بیفایده است اگر خود چرخه درآمد (RCM) دچار نشت ارزش باشد. یک پیشبینی با دقت ۹۵ درصد باید کارایی فرآیند وصول مطالبات را در نظر بگیرد.
۵.۱ تحلیل پیشبینیکننده برای مدیریت رد دعاوی (Denials)
رد دعاوی یکی از منابع اصلی نشت درآمد و خطای پیشبینی است. RCM سنتی پس از وقوع رد شدن دعوی واکنش نشان میدهد. پیشبینی با دقت بالا نیازمند مدیریت پیشبینیکننده رد دعاوی است.
مدلهای یادگیری ماشین میتوانند دادههای تاریخی دعاوی را برای شناسایی الگوهای مرتبط با رد شدن (مانند ترکیبات خاص کدهای CPT و پرداختکنندگان) تحلیل کنند. این مدلها قبل از ارسال، یک “امتیاز احتمال رد شدن” به دعاوی اختصاص میدهند.۳۶
- پاکسازی پیش از صورتحساب: دعاوی پرخطر برای بازبینی دستی یا اصلاح خودکار علامتگذاری میشوند.
- تعدیل پیشبینی: پیشبینی درآمد به جای فرض نرخ وصول ۱۰۰٪، بر اساس نرخ رد پیشبینیشده تعدیل میشود.
- تحلیل علت ریشهای: شناسایی مشکلات بالادستی (مانند خطاهای پذیرش، نقص در اخذ مجوزها) برای جلوگیری از رد شدنهای آینده.۸
۵.۲ امتیازدهی تمایل به پرداخت (Propensity to Pay – P2P)
با افزایش طرحهای بیمه با فرانشیز بالا، مسئولیت پرداخت بیماران به شدت افزایش یافته است. حسابهای پرداخت شخصی محرک اصلی بدهیهای بد هستند.
مدلهای P2P مبتنی بر هوش مصنوعی:
این مدلها از دادههای داخلی (تاریخچه پرداخت) و دادههای خارجی (امتیازات اعتباری، دموگرافیک اجتماعی-اقتصادی) برای محاسبه امتیاز تمایل به پرداخت برای هر بیمار استفاده میکنند.۱۶
- بخشبندی: بیماران به دستههای “احتمال بالای پرداخت”، “نیازمند کمک” و “ریسک بالای بدهی بد” تقسیم میشوند.
- بهینهسازی گردش کار: تلاشهای وصول مطالبات به سمت حسابهای با بازده بالا اولویتبندی میشوند، در حالی که حسابهای با P2P پایین در اوایل فرآیند به سمت مشاوره مالی یا خیریه هدایت میشوند.۳۷
- پیشبینی بدهی بد: امتیازات P2P مبنایی دقیق و دادهمحور برای تخمین ذخیره مطالبات مشکوکالوصول فراهم میکنند که به طور قابلتوجهی دقت پیشبینی درآمد خالص را بهبود میبخشد.۱۶
۵.۳ مدلسازی کسورات قراردادی
سیستمهای مدیریت قرارداد باید با موتور پیشبینی یکپارچه شوند. “PPOهای خاموش” و شرایط پیچیده قرارداد اغلب منجر به کمپرداختیهایی میشوند که شناسایی نمیشوند.
- محاسبه بازپرداخت مورد انتظار: سیستمهای پیشبینی باید بازپرداخت مورد انتظار برای هر پروسیجر زمانبندیشده را بر اساس شرایط قرارداد خاص پرداختکننده (شامل مقررات حد ضرر و استثنائات) محاسبه کنند.
- پایش واریانس: اختلافات بین بازپرداخت مورد انتظار و پرداخت واقعی باید برای شناسایی عدم عملکرد پرداختکننده یا خطاهای مدلسازی قرارداد تحلیل شوند.۳۶
فصل ششم: عوامل برونزا و تابآوری در برابر شوکهای اقتصادی
۶.۱ تأثیر تغییرات سیاستگذاری و CMS
مقررات دولتی و بهویژه مدیکر (CMS) به عنوان یک متغیر برونزای عظیم عمل میکنند. مدل پیشبینی که بهروزرسانیهای جدول تعرفه پزشکان مدیکر (PFS) یا سیستم پرداخت آیندهنگر بستری (IPPS) را در نظر نگیرد، اساساً ناقص خواهد بود.
محرکهای نظارتی کلیدی:
- کاهشهای بازپرداخت: قوانین پیشنهادی CMS برای سالهای آتی شامل تعدیلات کارایی و تغییرات ضریب تبدیل است که میتواند پرداختها برای تخصصهای خاص را کاهش دهد.۳۸
- بیطرفی مکان (Site Neutrality): سیاستهایی که هدفشان یکسانسازی پرداختها بین بخشهای سرپایی بیمارستانی (HOPDs) و مراکز جراحی سرپایی (ASCs) است، جریان درآمدی قابلتوجهی را برای بیمارستانها تهدید میکنند.۳۹
- تغییرات در بازپرداخت اقلام خاص: تغییر در نحوه بازپرداخت اقلام پرهزینه مانند جایگزینهای پوست (Skin Substitutes) میتواند هزینهها را به شدت کاهش دهد و شوک بزرگی به مراکز مراقبت از زخم وارد کند.۳۸
پیشبینیکنندگان باید برنامهریزی سناریو را انجام دهند تا تأثیر مالی این قوانین پیشنهادی را قبل از نهایی شدن مدلسازی کنند. این شامل تحلیلهای “چه میشود اگر” است: “اگر بیطرفی مکان اجرا شود، حاشیه سود بخش سرپایی ما چقدر تغییر خواهد کرد؟”.۳
۶.۲ شوکهای اقتصادی و تورم
هزینهها و درآمدهای بهداشت و درمان از نیروهای اقتصاد کلان مصون نیستند.
- تورم: تورم بالا هزینه نیروی کار (کمبود پرستار) و تجهیزات را افزایش میدهد. در حالی که درآمد اغلب توسط قراردادهای چند ساله ثابت است، هزینهها متغیر هستند. این فشردهسازی حاشیه سود باید مدلسازی شود.۴۲
- بیکاری: رکود اقتصادی منجر به از دست دادن بیمه تجاری میشود و ترکیب پرداختکنندگان را به سمت مدیکید و پرداخت شخصی تغییر میدهد. مدلهای پیشبینی باید نرخ بیکاری محلی را به عنوان یک متغیر برونزا برای پیشبینی تغییرات ترکیب پرداختکنندگان لحاظ کنند.۶
۶.۳ فصلی بودن و اپیدمیولوژی
حجم بیمارستان ذاتاً فصلی است.
- سه ماهه اول (Q1): فرانشیزهای بالا بازنشانی میشوند که اغلب منجر به کاهش حجم الکتیو و افزایش بدهی بد میشود (روزهای در حسابهای دریافتنی در ژانویه به اوج میرسد).۱۴
- سه ماهه چهارم (Q4): بیماران برای استفاده از مزایای باقیمانده بیمه خود هجوم میآورند که حجم الکتیو را افزایش میدهد.۵
- شیوع بیماری: فصول آنفولانزا و همهگیریها جهشهایی در بستریهای داخلی ایجاد میکنند اما ممکن است موارد جراحی سودآور را محدود کنند. مدلهای ترکیبی که از دادههای اپیدمیولوژیک استفاده میکنند میتوانند دقت پیشبینی را در طول این ناهنجاریها بهبود بخشند.۴۴
فصل هفتم: پیادهسازی فناورانه و عملیاتی؛ داشبوردها و MLOps
۷.۱ نقش داشبوردها و بصریسازی
یک پیشبینی تنها در صورتی ارزشمند است که قابل دسترسی و عملیاتی باشد. داشبوردهای بلادرنگ برای پایش عملکرد در برابر پیشبینی و شناسایی زودهنگام واریانسها ضروری هستند.
متریکهای کلیدی داشبورد (KPIs):
- روزهای در حسابهای دریافتنی (Days in A/R): شاخص پیشرو برای مشکلات جریان نقدی.۴۵
- نرخ دعاوی پاک (Clean Claim Rate): درصد دعاوی که در اولین ارسال پذیرفته میشوند. نرخ پایین نشاندهنده مشکلات کیفیت داده در بالادست است.۳۶
- نرخ رد (Denial Rate): باید بر اساس پرداختکننده و کد علت دستهبندی شود.
- درآمد خالص به ازای هر ترخیص تعدیلشده: یک معیار نرمالسازی شده برای عملکرد درآمد.
- هزینه وصول (Cost to Collect): کارایی تیم چرخه درآمد.۴۶
پلتفرمهایی مانند Tableau یا Power BI که با انبار داده یکپارچه شدهاند، به مدیران اجازه میدهند تا از متریکهای سطح سیستم به عملکرد فردی پزشک یا خط خدماتی نفوذ (Drill down) کنند.۴۷
۷.۲ عملیات یادگیری ماشین (MLOps)
استقرار مدلهای ML نیازمند یک خط لوله قوی عملیات یادگیری ماشین (MLOps) است. این اطمینان را ایجاد میکند که مدلها به طور مداوم بر روی دادههای جدید آموزش داده میشوند، برای “انحراف” (زمانی که دقت مدل به مرور زمان کاهش مییابد) پایش میشوند و به طور یکپارچه در تولید مستقر میشوند.۴۸
خط لوله پیشنهادی:
- ورود داده (Ingestion): استخراج، تبدیل و بارگذاری (ETL) خودکار از EHR/ERP.
- آموزش (Training): آموزش مجدد برنامهریزیشده مدلهای ARIMA/LSTM.
- اعتبارسنجی (Validation): تست خودکار گذشتهنگر (Back-testing) در برابر دادههای واقعی اخیر.
- استقرار (Deployment): ارائه پیشبینیها به داشبورد مالی.
- پایش (Monitoring): هشدار به دانشمندان داده در صورتی که نرخ خطا (MAPE) از آستانهها فراتر رود.۴۸
فصل هشتم: مطالعات موردی و موفقیتهای دنیای واقعی
۸.۱ کلینیک کلیولند: مدلسازی پیشبینیکننده برای بستری مجدد
کلینیک کلیولند (Cleveland Clinic) یک مدل امتیاز ریسک پیشبینیکننده را با استفاده از ۱۸ متغیر از EHR خود برای پیشبینی ریسک بستری مجدد توسعه داد. اگرچه این مدل در اصل بالینی است، اما پیامدهای مالی عمیقی تحت برنامههای مراقبت مبتنی بر ارزش (مانند برنامه کاهش بستری مجدد بیمارستان) دارد. با شناسایی دقیق بیماران پرخطر، آنها توانستند مداخلات هدفمندی انجام دهند، جریمهها را کاهش دهند و درآمد را حفظ کنند. این مدل حتی در طول همهگیری کووید-۱۹ دقت خود را حفظ کرد که نشاندهنده تابآوری ابزارهای پیشبینی مهندسیشده خوب است.۴۹
۸.۲ آلینا هلث (Allina Health): تمایل به پرداخت
سیستم سلامت آلینا (Allina Health) یک الگوریتم یادگیری ماشین را برای پیشبینی تمایل به پرداخت (P2P) حسابهای پرداخت شخصی پیادهسازی کرد. با بخشبندی بیماران و متناسبسازی استراتژیهای وصول (مانند تماسهای تلفنی در برابر نامههای خودکار)، آنها به افزایش ۲ میلیون دلاری در وصولیها در یک سال و بهبود ۴۳ درصدی در عملکرد وصول تلفنی دست یافتند. این امر مستقیماً دقت پیشبینی درآمد خالص را با تبدیل تخمینهای “بدهی بد” به درآمد قابل تحقق بهبود بخشید.۳۷
نتیجهگیری: مسیر دستیابی به دقت ۹۵ درصد
دستیابی به دقت ۹۵ درصد در پیشبینی درآمد بیمارستان، تلاشی چندوجهی است که فراتر از مدلسازی ساده با صفحات گسترده میرود. این امر نیازمند همگرایی مهندسی دادههای با یکپارچگی بالا، معماریهای الگوریتمی ترکیبی پیشرفته و بینش استراتژیک عمیق نسبت به نیروهای نظارتی و اقتصادی شکلدهنده بهداشت و درمان است.
توصیههای استراتژیک و عملیاتی:
- کنار گذاشتن بودجههای ایستا: فوراً به سمت پیشبینیهای غلتان حرکت کنید تا پویایی بازار را ثبت کنید.
- پاکسازی دادهها: در OMOP CDM و MPI سرمایهگذاری کنید تا اطمینان حاصل شود که دادههای تغذیهکننده مدلها پاک و استاندارد هستند.
- پذیرش مدلهای ترکیبی: معماریهای آنسامبل (ARIMA-LSTM) را برای ثبت همزمان فصلی بودن خطی و روندهای غیرخطی پیچیده پیادهسازی کنید.
- مدیریت هوشمند چرخه درآمد: از تحلیلهای پیشبینیکننده برای جلوگیری از رد دعاوی و بهینهسازی وصولیها (P2P) استفاده کنید، زیرا تحقق درآمد به اندازه تولید درآمد مهم است.
- پایش شوکهای خارجی: سناریوهای نظارتی و شاخصهای اقتصادی را در منطق پیشبینی ادغام کنید تا تابآوری مالی را تست استرس کنید.
با تلقی پیشبینی نه به عنوان یک تمرین حسابداری منفعل، بلکه به عنوان یک دیسیپلین استراتژیک فعال که توسط هوش مصنوعی و علم داده قدرت میگیرد، بیمارستانها میتوانند با اطمینان در عدم قطعیت مالی حرکت کنند و اطمینان حاصل کنند که منابع لازم برای انجام مأموریت اصلی خود—یعنی مراقبت از بیمار—را در اختیار دارند.
پیوست فنی: مبانی ریاضی مدلهای پیشبینی
الف.۱ مشخصات مدل ARIMA
مدل ARIMA$(p,d,q)$ به صورت زیر تعریف میشود:
$$\left(1 – \sum_{i=1}^p \phi_i L^i\right) (1 – L)^d X_t = \left(1 + \sum_{j=1}^q \theta_j L^j\right) \epsilon_t$$
که در آن:
- $L$ عملگر تأخیر (Lag operator) است.
- $\phi_i$ پارامترهای بخش خودهمبسته (Autoregressive) هستند.
- $\theta_j$ پارامترهای بخش میانگین متحرک (Moving Average) هستند.
- $\epsilon_t$ نویز سفید است.
الف.۲ معماری سلول LSTM
معادلات اصلی برای یک سلول LSTM در زمان $t$:
$$f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) \\ i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \\ \tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) \\ C_t = f_t * C_{t-1} + i_t * \tilde{C}_t \\ o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)$$
$$h_t = o_t * \tanh(C_t)$$
این دروازهها (فراموشی، ورودی، خروجی) به LSTM اجازه میدهند جریان اطلاعات را تنظیم کند و آن را برای ثبت روندهای درآمدی طولانیمدت و تغییرات ساختاری در دادههای بهداشتی برتر میسازد.
بیشتر از بیشینه سازان درآمد سلامت کشف کنید
برای دریافت آخرین پستها به ایمیل خود مشترک شوید








 بیمارستان خود را با دقت ۹۵ درصد انجام دهیم؟){kind=link}
بدون دیدگاه